-
[논문 리뷰] PointPillars: Fast Encoders for Object Detection from Point Clouds (1)Autonomous Navigation/Perception 2021. 9. 3. 00:00
PointPillars의 작동 방식을 대강 요약하면 다음과 같습니다.
포인트 클라우드 데이터를 적절히 조작하여 2-D 이미지와 비슷한 특성을 지니는 Pseudoimage로 만든 후 이 데이터에 우수한 CNN 기반 object detector를 적용하자!
PointPillars의 개념도 포인트 클라우드는 sparse하고(비어있는 공간이 많습니다), 각각의 점들이 위치 정보만을 갖고 있으며, 3차원 데이터이기 때문에 컨볼루션 신경망을 적용하기가 쉽지 않습니다. 이미지 데이터에서의 컨볼루션 신경망을 그대로 3차원으로 확장하여 3차원 컨볼루션 필터를 사용한 연구들이 있었으나, 이러한 방식은 일단 포인트 클라우드를 복셀화(voxelization)해야 하는 번거로움이 있으며 3차원 컨볼루션의 큰 연산량 때문에 학습과 inference가 모두 오래 걸리는 특성이 있습니다(게다가 sparse하기 때문에 이 3차원 컨볼루션 필터는 대부분의 영역에서 쓸데없는 연산을 하고 있습니다). PointNet을 기반으로 3차원 컨볼루션 필터를 적용해 3D object detection을 시도한 VoxelNet은 작동 속도가 고사양 PC에서도 4~5Hz 정도였다고 합니다.
PointPillars는 3차원이고, sparse하며, unordered 데이터인 포인트 클라우드를 이미지 데이터와 비슷한 2차원 ordered 데이터인 pseudoimage로 변환합니다. 이것이 사실상 PointPillars의 핵심이라 할 수 있으며, 나머지는 현존하는 CNN 기반 object detector들의 응용입니다.
PointPillars의 전체 구조는 다음과 같습니다. Pillar feature net이 pseudoimage로 변환하는 역할의 네트워크입니다.

가장 중요한 단계인 Pillar feature net의 구조와 원리에 대해 이야기해 보겠습니다.
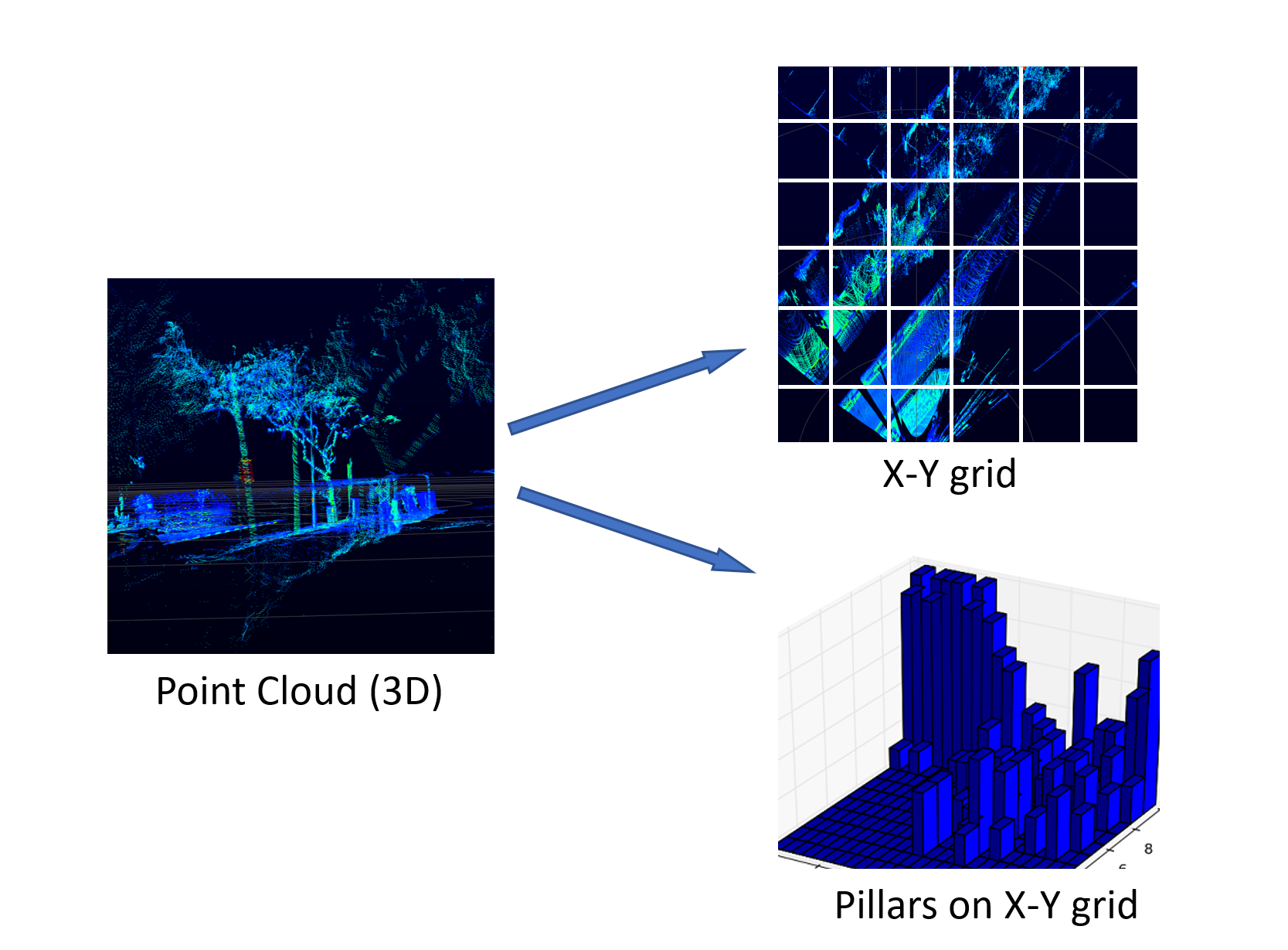
첫 번째로, 포인트 클라우드 양자화 단계에서는 x-y plane을 간격이 일정한 grid로 나누고 각각의 grid cell 안에 들어 있는 포인트들을 같은 그룹으로 묶습니다. 이것이 마치 땅에 닿은 면적이 좁고 위쪽으로 쌓여 있는 모양과 같다고 하여 pillar라는 이름이 붙게 되었습니다. 만약 관심영역인 x-y plane의 영역을 $ N $개로 나누었다면 $ N $개의 pillar가 생성됩니다.
두 번째로는 각각의 pillar에 속하는 point에 $ x, y, z $좌표 이외에 추가적인 정보들을 붙입니다. LiDAR 가 측정한 intensity $ \gamma $, pillar 내부 point들의 좌표 평균으로부터의 거리 $ x_{c}, y_{c}, z_{c} $, pillar의 $ x, y $ 중심으로부터의 offset인 $ x_{p}, y_{p} $를 좌표 뒤에 붙여서 9-D 벡터로 만듭니다.
세 번째로는 이러한 9-D 벡터를 포함하는 $ N $ 개의 pillar 들을 사용해 dense한 tensor를 생성합니다. 구체적으로는 $(D, P, N)$ 크기의 tensor를 생성하는데, $ P $는 이 tensor안에 포함될 수 있는 non-empty pillar의 최대 개수, $ N $은 하나의 pillar안에서 뽑힐 point들의 최대 개수를 뜻합니다. point가 너무 적거나 많으면 0으로 채우거나 무시합니다.
네 번째에서는 PointNet의 간단한 버전으로 만든 뉴럴넷에 이 tensor를 집어넣고 돌려 $ (C, P, N) $크기의 tensor를 생성합니다. 이 과정을 통해 각각의 pillar에서 feature들이 생성됩니다.
마지막으로 이 feature들을 원래 점들의 위치로 돌려 놓습니다. 그러면 $ (C, H, W) $ 크기의 배열이 생성되는데, 이것을 pseudo-image라고 부르며 원래 포인트 클라우드의 local과 global feature들을 인코딩해놓은 데이터라고 볼 수 있습니다. 각 포인트마다 C개의 feature를 가지고 있다는 것인데, 이게 뭔지 우리가 알 수는 없습니다. 그냥 뉴럴넷이 알아서 중요한 정보들을 지만 아는 식으로 인코딩 해놓았겠지... 라고 바랄 뿐입니다.
이렇게 해서 unordered, sparse한 데이터로부터 ordered, dense한 데이터인 pseudoimage를 생성했습니다. 이제 이 데이터에 대해 널리 쓰이는 CNN object detector를 적용하면 됩니다! 논문에서는 backbone과 detection head라고 하는데, 채널이 3개가 아닌 C개라는 점만 제외하면 아래와 같이 일반적인 CNN detector에서의 FPN(Feature Pyramid Network)와 거의 같다고 보면 되는 구조입니다. 논문에서는 SSD(Single Shot Detector)를 가져다 썼습니다.

PointPillars는 2D 컨볼루션 필터를 사용했으며 그 밖에도 무거운 연산이 많이 없는 등의 특징으로 아주 빠르게 동작이 가능한 점이 특징입니다. 그럼에도 불구하고 SOTA 정확도를 달성했으며, 자율 주행 분야에서의 많은 응용이 기대되는 방식입니다.
'Autonomous Navigation > Perception' 카테고리의 다른 글
Particle Filter를 이용한 Monte Carlo Localization (0) 2021.09.19 [논문 리뷰] PointPainting: Sequential Fusion for 3D Object Detection (0) 2021.09.03 [논문 리뷰] PointPillars: Fast Encoders for Object Detection from Point Clouds (0) (0) 2021.09.02 [논문 리뷰] PointNet (2) : 포인트 클라우드를 다루기 위한 딥 러닝 네트워크의 구조 (0) 2021.09.02 [논문 리뷰] PointNet (1) : 포인트 클라우드의 기초 (0) 2021.09.01