-
다중 객체 추적(MOT) 시스템 - Data AssociationAutonomous Navigation/Perception 2021. 8. 26. 14:37
2021.08.25 - [Autonomous Navigation/Perception] - 다중 객체 추적(MOT) 시스템의 구성 요소
다중 객체 추적(MOT) 시스템의 구성 요소
2021.08.25 - [Autonomous Navigation/Perception] - 다중 객체 추적(Multi Object Tracking) 다중 객체 추적(Multi Object Tracking) 자율 주행 시스템에 필수적인 인지 능력 중 하나는 객체 추적 능력입니다. 객..
wjdghksdl26.tistory.com
지난 글에서 알아보았듯 data association은 다중 객체 추적 시스템에서 가장 중요하고 어려운 부분입니다. 해당 알고리즘의 성능에 따라 전체 시스템의 성능이 좌우되는 경우가 많습니다.
일반적으로 data association 알고리즘에서는 추적할 각각의 물체를 점, 즉 하나의 좌표로 표현할 수 있는 객체라고 가정합니다. RADAR나 LiDAR 센서 같은 경우에는 해상도가 높은 경우 하나의 물체(자동차 등) 이라도 하나 이상의 sensor measurement로 표현되기도 합니다. 이 개념을 extended object라고 합니다.
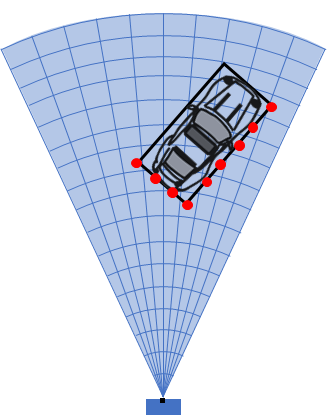
Extended object - 레이더에 포착된 자동차는 여러 개의 measurement로 관측됨(빨간 점들) 따라서, 이런 경우에 data association을 위해서는 일단 군집화(clustering) 방법을 사용해서 저러한 여러 개의 관측값을 하나의 물체로 인식하고 하나의 좌표로 나타낼 필요가 있습니다. 관측값 군집화는 딥러닝을 사용하던, DBSCAN이나 K-means 등을 사용하던 목적에 맞는 것을 찾아 쓰면 됩니다. 그 후에 형성된 군집들의 위치, 방향, 크기, 형상 등등 필요한 정보들을 모아 벡터로 나타내면 객체를 하나의 좌표로 표현한 것이 됩니다. 어떤 방법을 써서든 이것이 가능해졌다면 이제 data association 알고리즘에 객체들을 넘겨 주면 됩니다. 다음 그림을 통해 data association의 기본적인 개념을 알아보겠습니다.

일단 칼만 필터가 이전의 상태로부터 예측해낸 현재 물체의 예상 위치가 $ T_{1} $이라고 합시다. 이것은 이전 상태가 정확하고 물체가 완벽하게 칼만 필터의 운동 모델을 따라 이동한다고 했을 때 예측되는 위치입니다. 그러나 당연하게도 현실 세계에서는 그럴 리가 없기 때문에 그 불확실성을 공분산 행렬로 나타냅니다. 그것이 $ T_{1} $을 중심으로 그려져 있는 타원, 즉 validation gate 입니다. 이 타원의 의미는, $ T_{1} $의 예측 위치가 100% 확실하지는 않지만 이 타원 안쪽에 있을 확률이 매우 높다는 뜻입니다(타원의 크기는 예측을 얼마나 보수적으로 믿느냐에 따라 늘였다 줄였다 할 수 있습니다). 이걸로부터 관측값 $ O_{4}, O_{5}, O_{6} $을 걸러낼 수 있습니다.
그러나 애석하게도 validation gate 안에도 관측값이 3개나 존재합니다. 과연 이것들 중에 어떤 것이 우리가 추적하던 물체로부터 나온 관측값일까요?? 어떤 기준으로 3개 중 맞는 관측값을 선택해야 할까요?? 이 기준을 어떻게 잡느냐에 따라서 data association 알고리즘들의 종류와 특성이 결정됩니다. 이 글에서는 GNN, JPDA, TOMHT 알고리즘에 대해 간략히 살펴보겠습니다.
GNN(Global Nearest Neighbor) 알고리즘은 매우 간단합니다. 그냥 제일 가까이 있는 관측치를 참값이라고 추정합니다. "가까이 있는"의 기준은 tracker를 만드는 사람이 결정하면 되는데, 그냥 물리적인 거리를 취할 수도 있고, 지난 글에서 설명한 형상 묘사 벡터 간의 거리를 추가하거나 하는 방법도 생각해볼 수 있겠습니다.

방금 언급되었듯, 문제는 Figure 2와 같은 상황에 생깁니다. 한 track의 observation gate 안에 여러 detection들이 있거나, 하나의 detection이 여러 track에 연관되는 경우입니다. 이럴 때는 각각의 detection에 대해 "점수"를 매겨서 판단을 해야 합니다. 점수(또는 cost)를 매기는 방법은 여러 가지 생각해볼 수 있겠으나(직접 cost function을 만들어도 되겠죠?) 보통은 다음과 같은 식을 널리 사용합니다.
$ C_{ij} = d_{ij} + \ln (\left | S_{ij} \right |) $
$ i $가 track number, $ j $가 detection, $ d_{ij} $는 마할라노비스 거리(Mahalanobis distance), $ S_{ij} $는 residual covariance matrix의 행렬식입니다. Residual covariance matrix는 칼만 필터의 update step에서의 innovation covariance를 말하는 것으로, 측정과 예측에 의한 불확실성을 나타냅니다. 즉 $ \ln (\left | S_{ij} \right |) $의 존재는 불확실성이 큰 association에 낮은 점수(=높은 cost)를 주기 위한 term입니다. 이러한 Cost를 Figure 2의 상황에 대해 계산해 보면 다음과 같습니다.

이제 total cost를 최소화하는 association을 잘 찾으면 됩니다(물론 잘 찾는 방법도 Hungarian method, Munkres method 등 여러 가지가 있습니다ㅋㅋㅋ). 이것을 할당 문제(assignment problem)이라고 하는데, 다중 객체 추적 외에도 여기저기 쓸모가 많은 문제이기 때문에 검색해 보시면 좋은 자료를 많이 얻을 수 있습니다. 실제로는 매 iteration마다 이런 상황이 발생하거나 하는 경우는 엄청 바글바글한 상황(군중 추적 등)을 제외하면 잘 없기 때문에 가끔씩 한 번 일어날 상황에 대비한다고 생각하면 되겠습니다. 물론 이러한 예외 상황을 handling하는 절차가 많을수록 정확도는 높아지지만 계산 자원의 소모가 많아지겠죠??
JPDA(Joint Probability Data Association) 알고리즘은 좀더 복잡합니다. GNN과는 달리 JPDA는 association을 확정짓지 않고, validation gate 내의 모든 detection들에 대해 association probability를 계산합니다. 그리고 이 probability들을 이용하여 residual의 weighted sum을 계산한 후, 이것을 칼만 필터의 correction step에서 residual(=innovation) 대신 사용합니다. 즉, validation gate 안의 어떤 detection이 맞는 것인지 모르니 각각의 feasibility를 모두 따져서 update(=correction)에 사용하겠다는 말입니다. 당연히 이런 방식은 sub-optimal합니다(언제나 100% 정확하지도 100% 틀리지도 않습니다).
TOMHT(Track-Oriented Multiple Hypothesis Tracking) 알고리즘은 위의 두 알고리즘과 달리 hypothesis, 즉 가설을 설정합니다. Validation gate 안에 detection이 3개 있다면, 가설 3개를 세워 놓고 다음 time step으로 진행한 후 또 각각의 가설에 대해 여러 개의 가설을 설정합니다. 당연히 이러면 가설의 수가 급격하게 늘어나기 때문에 각각의 가설에 대한 probability를 계산해서 문턱값 이하의 확률을 가진 가설들은 가지치기를 합니다(probability를 계산하는 방법도 잘 만들어야겠죠?).
---------- 개인적인 의견 ----------
저도 사실 직접 구현할 만큼 알고 있는 알고리즘은 GNN밖에 없습니다.... JPDA와 TOMHT는 어떤 컨셉인지는 알지만 구체적인 구현 방식은 더 공부해 봐야 알 것 같습니다.
듣기로는, 최근에는 영상 데이터 처리 쪽에서는 딥 러닝 기술이 하도 다양하게 발전하다 보니 appearance description vector 같은 것들을 상당히 우수하게 뽑아낼 수 있고, 이것들을 detection간에 매칭하는 것만으로도 assignment가 매우 정확하게 이루어진다고 합니다. 그래서 GNN으로도 높은 정확도의 tracking이 된다는 것이 최근의 추세 같습니다. 이런 걸 뽑을 수 없는 RADAR detection 같은 경우에는 JPDA와 TOMHT 등의 방법을 사용해야 한정된 데이터 입력만으로 정확한 추적이 가능할 것 같습니다.
'Autonomous Navigation > Perception' 카테고리의 다른 글
[논문 리뷰] PointNet (1) : 포인트 클라우드의 기초 (0) 2021.09.01 [논문 리뷰] PointNet : Deep Learning on Point Sets for 3D Classification and Segmentation (0) (0) 2021.09.01 다중 객체 추적(MOT) 시스템 - Gating에 대한 조금 더 자세한 설명 (0) 2021.08.27 다중 객체 추적(MOT) 시스템의 구성 요소 (0) 2021.08.25 다중 객체 추적(Multi Object Tracking) (0) 2021.08.25